机器之心 SOTA!模型社区专栏
作者:Jiying
专栏编辑:之乎、 雅芳、小土同学

本专栏由机器之心SOTA!模型社区出品,每周日于机器之心公众号持续更新。
BELLE、ChatGLM、白泽、社区版中文羊驼和 MOSS,哪个项目的 10B 量级模型逻辑推理得更好?
在数字的海洋中,排行榜和指标告诉我们哪个模型可能更优越,但这些数字并不足以满足我们。
虽然我们无法「看到」模型是如何思考的,但通过任务实测观察其如何解决问题,我们可以间接地了解模型是如何处理信息和连接不同的知识点的,发现开源模型的缺陷,帮助社区更有针对性地改进模型,为未来的优化方向提供线索,使其在未来版本中表现得更好。
上期我们实测的是语义理解的理解能力,本期我们要实测的是逻辑问题的推理能力。逻辑推理是评估模型在理解和推断语言中的逻辑关系和推理能力方面的任务。逻辑推理任务涉及对语句之间的逻辑关系、前因后果、条件和假设进行分析和推理。通过逻辑推理任务的实测,我们可以判断模型在处理逻辑结构、推理关系和逻辑演绎等方面的能力,以及对复杂逻辑问题的解决效果。
在这个《不测不知道 - 10B 量级开源中文对话模型》系列中,我们将对 10B 量级的开源中文对话模型,针对数学能力、语义理解和中文尝试及逻辑推理开展实测,尝试在传统的基准测试指标及排行榜名次之外,为老伙计们提供另一种探索开源模型的「魔改」可用性的视角。
为何选择 10B 量级的模型呢?关注 10B 量级的模型,实际上是对资源效率、可行性和部署成本等实际基于开源方案进行 AIGC 应用开发的工程师们所关注的问题。因此,我们将持续对目前能找到的热门 10B 量级中文对话、指令微调的开源模型进行实测,尝试探索不同基座模型、不同微调方案的它们在性能有什么差别?
本期实测的 10B 量级中文对话模型依然来自 BELLE、ChatGLM、Baize、Panda、中文民间版羊驼和Moss这几个项目。
注:由于在完成这篇约稿时 Llama2还没发布,因此当时实测选择的模型版本都是于今年上半年发布的。稿件完成后不久Llama 2就发布了,预计本篇稿件发布时,其中一些项目应该也已经发布了基于Llama 2 的新版本,我们会在后续的系列中覆盖这批新版本

以上模型均部署在某国内头部公有云厂商的云服务器上进行的实测,硬件资源情况如下:
CPU&内存:12核(vCPU) 92 GiB
GPU:Nvidia V100 32GB
逻辑推理任务:实测方案
逻辑推理任务主要考察模型回答逻辑推理问题的能力,涉及语句之间的逻辑关系、前因后果、条件和假设进行分析和推理。
本次实测共设置了 4 个逻辑推理题。选题范围是小学高年级到初中一年级阶段的逻辑题,从小初的测试题中选取,并根据在小初测试卷中的难度划分为高级难度、中级难度、低级难度。
要注意的是,这个高级、中级、低级难度是小初阶段针对孩子的逻辑思维能力进行评估划分的。在实测结果中我们会看出,模型认为任务的难度等级,似乎跟人类的判断并不一致。
在本次实测过程中,我们对每一个模型的任务完成情况进行了打分,以便于量化分析,分数为「0,0.5,1」三种情况。
对于能够正确回答的情况,我们给结果打分为「1」分。
对于并没有给出正确答案,但是明显理解了问题,在尝试努力回答的情况,我们给结果打分为「0.5」分。
对于完全胡乱回答、明显没有理解问题的情况,我们给结果打分为「0」分。
TL;DR 实测结果
在本期实测中,效果最好的是 BELLE-7B-1M、ChatGLM 系列模型。效果最差的则是白泽系列模型和 BELLE-LLaMA-EXT-7B。得分较高的 BELLE-7B-1M、ChatGLM、Panda 的回答情况基本是全部理解了问题,一半能答对,一半答错。
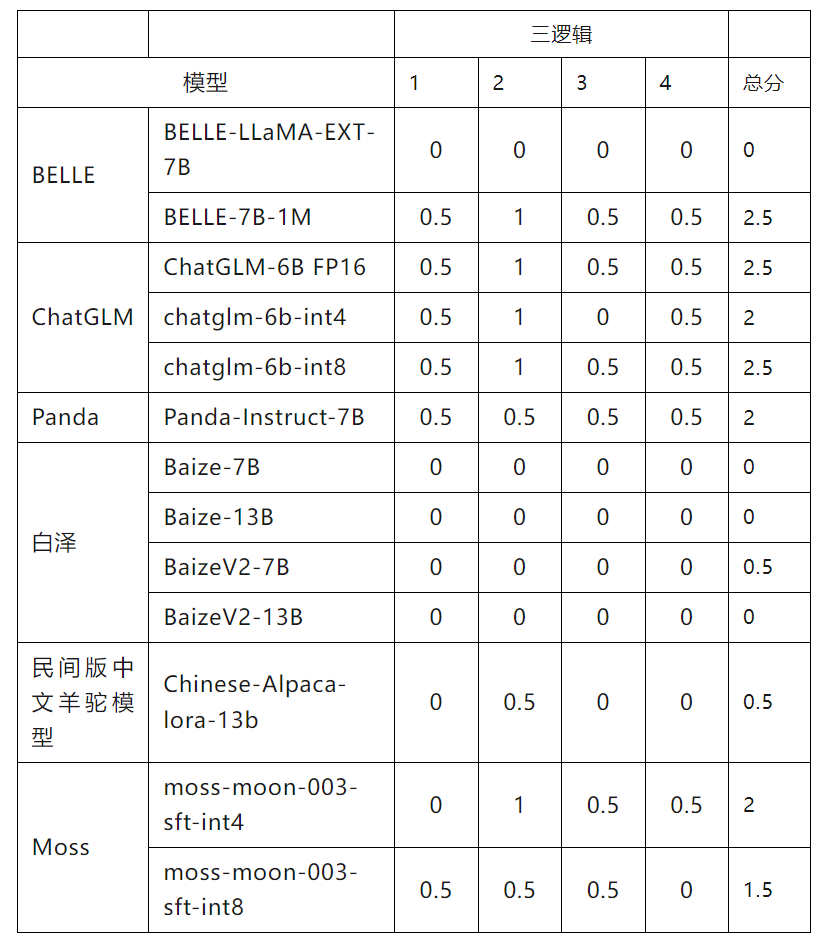
本次实测中,最让我们没有想到的是,模型对于逻辑推理问题的难易程度判断与人类不同。我们原想的第 2 个高难度逻辑推理任务,BELLE-7B-1M、ChatGLM 竟然都答对了,但是这些模型却无法完成中级和低级难度的推理任务。
实测 # 1 逻辑推理(高级难度)
某仓库失窃,四个保管员因涉嫌而被传讯,四个人的供述如下:甲:我们四个人都没作案;乙:我们中有人作案;丙:乙和丁至少有一人没作案;丁:我没作案。如果四个人中有两人说的是真话,有两人说的是假话,则以下哪项判定成立?( )
A. 说真话的是甲和丁
B。说真话的是乙和丙
C。说真话的是甲和丙
D。说真话的是乙和丁
没有模型正确完成了这个逻辑推理任务,有一些模型在一本正经的“推理”,然后根据自己的逻辑得出了一个错误的答案。


实测 #2 逻辑推理(高级难度)
一本小说要畅销,必须有可读性;一本小说只有深刻触及社会敏感点,才能有可读性;而一个作者如果不深入生活,他的作品就不可能深刻触及社会敏感点,以下哪项结论可以从题干的断定中推出?I. 一个畅销小说的作者,不可能不深入生活。II. 一本不触及社会敏感点的小说,不可能畅销。III.一本不具有可读性的小说的作者,一定没有深入生活。
A. 只有 I
B.只有 II
C.只有 III
D.只有 I 和 II
在这推理题中,只有 ChatGLM 系列和一个 BELLE、一个 Moss 模型成功完成了这个逻辑推理任务。


实测 # 3 逻辑推理(中级难度)
李明、王宁、张虎三个男同学都各有一个妹妹,六个人在一起打羽毛球,举行混合双打比赛。事先规定:兄妹二人不许搭伴。
第一盘,李明和小华对张虎和小红;第二盘,张虎和小林对李明和王宁的妹妹。
请问,小华、小红和小林各是谁的妹妹?
这个逻辑推理任务对于小初阶段的孩子来说难度并不高,但模型的完成效果不如任务 2,没有一个模型能够正确的推理。


实测 #4 逻辑推理(低级难度)
A、B、C、D 四人,已知 B 不是最高的,但他比 A、D 高,而 A 不比 D 高,请把他们按高矮排列。
这个原本认为难度最低的推理任务,依然没有任何模型能够答对。对于人类来说,这种高矮的排序只需要两两比较就可以简单的判断,但很显然,模型做不到。


本期的实测就到这里,下一期我们将继续就以上六个模型的其他能力进行实测及讨论。
你是否曾对排行榜的模型产生过疑问,或在魔改过程中对某一模型的能力边界产生怀疑?欢迎扫描下方海报中的二维码加入「魔改小组」,与社区老伙计们共同分享彼此使用开源模型的实测、魔改经验,一起探索更加先进的开源模型魔改方案。
附录:本期实测项目介绍
BELLE 项目
BELLE是Be Everyone's Large Language model Engine的缩写,是一个开源的中文对话大模型,是由LianjiaTech开发完成的。BELLE基于斯坦福的 Alpaca 完成,但进行了中文优化,并对生成代码进行了一些修改。
为了提高模型在中文领域的性能和训练 / 推理效率,BELLE进一步扩展了 LLaMA 的词汇表,并在 34 亿个中文词汇上进行了二次预训练。此外,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。基于 ChatGPT 产生的指令训练数据方式有:1)参考 Alpaca 基于 GPT3.5 得到的 self-instruct 数据;2)参考 Alpaca 基于 GPT4 得到的 self-instruct 数据;3)用户使用 ChatGPT 分享的数据 ShareGPT。
项目亮点
研究报告:从指令微调策略到模型评估范式等多方面探究提升大语言模型指令表现能力的因素
数据开放:丰富、大量且持续完善的训练和评估数据
开箱即用的多种模型和指令微调 / LoRA / 量化代码
多终端 LLM 推理和聊天 app,无需联网,离线运行
本次实测使用的版本包括BELLE-LLaMA-EXT-7B和BELLE-7B-1M,均为以LLAMA-7b(70亿参数)为基础进行指令微调后得到的模型。
SOTA!模型项目详情页
https://sota.jiqizhixin.com/project/belle
Github 项目代码仓库
https://github.com/LianjiaTech/BELLE
ChatGLM-6B 项目
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化,由清华大学的研究团队开发。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。GLM的核心是:Autoregressive Blank Infilling,即,将文本中的一段或多段空白进行填充识别。
结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
项目亮点
生成质量:相较于传统的聊天AI模型,ChatGLM-6B在生成质量方面表现出色。它能够生成更加自然、流畅且贴近人类的对话,提供了更好的用户体验。
对话逻辑:ChatGLM-6B在对话逻辑方面的改进也是显著的。传统聊天AI往往会给出不连贯或无关的回应,而ChatGLM-6B则能更好地理解上下文,并生成有逻辑性的回复。
开放性:ChatGLM-6B是一个开源项目,这意味着研究者和开发者可以自由地使用、修改和分发该模型。这有助于推动聊天AI领域的发展和创新。
人类意图对齐训练:使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
充分的中英双语预训练:ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
优化的模型架构和大小:吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
本次实测使用的版本包括ChatGLM-6B FP16、chatglm-6b-int4和chatglm-6b-int8。
SOTA!模型项目详情页
https://sota.jiqizhixin.com/project/chatglm
Github 项目代码仓库
https://github.com/THUDM/ChatGLM-6B
Panda 项目
Panda是新加坡南洋理工的研究团队以LLaMA为基础模型,采用了两阶段训练方法开发的中文大语言模型。Panda LLM网络基于Transformer架构。利用各种改进来增强模型,包括预归一化、SwiGLU激活函数和旋转嵌入等。
为了让Panda LLM在中文数据集上获得强大的性能,作者使用了强大的指令微调instruction-tuning技术,将LLaMA基础模型在五个开源的中文数据集进行混合训练,其中包括来自各种语言领域的1530万个样本,例如维基百科语料,新闻语料,百科问答语料,社区问答语料和翻译语料。
本项目亮点:
本项目采用了两阶段训练方法:首先在五大中文语料进行训练微调,其次在少量且多样的数据上进行指令微调。该训练方法取得了非常棒的结果,并超越了以往所有可用的具有相同参数数量的中文开源大型语言模型。
本项目首次对各种中文开源大型语言模型进行了比较评估。
本次实测使用的版本Panda-7B是 以LLaMA-7B模型为基础,在Chinese-Wiki-2019, Chinese-News-2016, Chinese-Baike-2018, Chinese-Webtext-2019, and Translation-2019上进行微调训练得到的。
SOTA!模型项目详情页
https://sota.jiqizhixin.com/project/panda-4
Github 项目代码仓库
https://github.com/dandelionsllm/pandallm
白泽 Baize 项目
来自加州大学圣迭戈分校、中山大学和微软亚研的研究者提出了「白泽」。白泽目前包括四种英语模型:白泽 -7B、13B 和 30B(通用对话模型),以及一个垂直领域的白泽 - 医疗模型,供研究 / 非商业用途使用,并计划在未来发布中文的白泽模型。白泽的数据处理、训练模型、Demo 等全部代码已经开源。目前,「白泽」支持 20 种语言,对于英语以外的内容质量有限,继承了 LLaMA 的知识,可能会出现幻觉,或用过时知识进行回答。
项目亮点
作者采用了有效利用计算资源的参数高效调优方法。该策略使最先进的语言模型保持了高性能和适应性。白泽改进了开源大型语言模型 LLaMA,通过使用新生成的聊天语料库对 LLaMA 进行微调,该模型在单个 GPU 上运行,使其可供更广泛的研究人员使用。
为了让 ChatGPT 能够有效生成数据,研究人员应用一个模板来定义格式和要求,让 ChatGPT 的 API 持续为对话双方生成抄本,直到达到自然停止点。对话以「种子」为中心,「种子」可以是一个问题,也可以是设置聊天主题的关键短语。通过这样的方法,研究人员分别收集了 5 万条左右 Quora、StackOverflow(编程问答)和 MedQA(医学问答)的高质量问答语料,并已经全部开源。
本次实测使用的版本包括Baize-7B、Baize-13B、BaizeV2-7B以及BaizeV2-13B。
SOTA!模型项目详情页
https://sota.jiqizhixin.com/project/baize
Github 项目代码仓库
https://github.com/project-baize/baize
中文社区版羊驼项目
经典的LLaMA模型是Meta(Facebook)开源的大模型,有很多不同的尺寸,13B及以上的模型达到了匹敌和超过GPT3的能力,但是不能chat。
通过询问chatGPT,使用178个问题生成62k标准数据训练后,使得LLaMA具备了对话功能--Alpaca。在此之后利用LoRA,使用葡萄牙语训练 具有对话功能的LLaMA,来获取跨语言的能力,得到了Alpaca模型。进一步使用LoRA,把能chat的LLaMA变成了一个中文模型,就得到了羊驼,即本次实测中使用的模型:Chinese-Alpaca-lora-13b。
具体来说,在获得预训练的中文LLaMA模型后,按照Alpaca中使用的方法,应用自我训练的微调来训练指令跟随模型。每个例子由一条指令和一个输出组成。将指令输入模型,并提示模型自动生成输出。此外,使用LORA进行参数有效的微调,通过在MLP层添加LoRA适配器来增加可训练参数的数量。
项目亮点:
通过在原有的LLaMA词汇中增加20,000个中文符号来提高中文编码和解码的效率,并提高LLaMA的中文理解能力。
采用低秩适应(LoRA)的方法来有效地训练和部署中国的LLaMA和Alpaca模型,使研究人员能够在不产生过多计算成本的情况下使用这些模型。
SOTA!模型项目详情页
https://sota.jiqizhixin.com/project/chinese-llama-alpaca-2
Github 项目代码仓库
https://github.com/ymcui/Chinese-LLaMA-Alpaca
MOSS 项目
MOSS是复旦大学自然语言处理实验室发布的国内第一个对话式大型语言模型。MOSS可执行对话生成、编程、事实问答等一系列任务,打通了让生成式语言模型理解人类意图并具有对话能力的全部技术路径。
MOSS 是一个支持中英双语和多种插件的开源对话语言模型,moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100 / A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
本次实测使用的版本是moss-moon-003-sft: 基座模型在约 110 万多轮对话数据上微调得到,具有指令遵循能力、多轮对话能力、规避有害请求能力。
SOTA!模型项目详情页
https://sota.jiqizhixin.com/project/moss
Github 项目代码仓库
https://github.com/OpenLMLab/MOSS
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。