
MaPU架构通过“软件定义硬件”的动态重构能力,结合3D堆叠技术对互连与集成方式的革新,正在重写芯片设计的底层规则——从追求单一场景的极致效率转向灵活性、能效与扩展性的统一。
一、传统架构的瓶颈与MaPU的突破
传统芯片设计长期受困于“效率与灵活性不可兼得”的难题:
1. ASIC的局限性:虽在特定任务(如AI推理)中能效极高,但功能固化导致无法适应算法快速迭代,设计成本与风险居高不下。
2. GPU/CPU的通用性代价:依赖共享内存和复杂调度,资源利用率普遍低于50%,且功耗随规模扩展急剧上升。
3. FPGA的折中缺陷:可重构但编程复杂,动态调整耗时,难以满足实时计算需求。
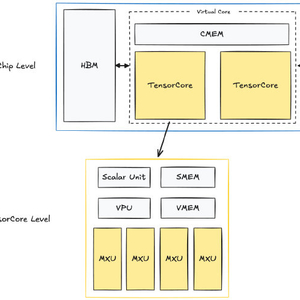
MaPU架构以代数指令软流水线为核心,实现“零延时动态重构硬件”:
- 根据运算任务需求,通过软件指令实时调整硬件资源分配,使内核利用率达90%以上;
- 融合ASIC的能效与CPU/GPU的灵活性,形成“软ASIC”模式,可跨科学计算、通信、生物医药等多场景高效适配。
二、3D堆叠如何为MaPU提供物理基础
3D堆叠技术从空间维度突破平面集成限制,解决MaPU架构对高带宽、低延迟的刚性需求:
1. 垂直互连革新:
- 通过硅通孔(TSV)技术实现10μm级互连密度,将芯片间数据传输延迟降至5ns级,提升异构计算单元协作效率;
- 苹果M1 Ultra、华为海思芯片已验证该路径的性能增益(如AMD 3D V-Cache提升游戏性能15%)。
2. 异构集成新范式:
- CPU、NPU、内存单元垂直堆叠,形成“计算-存储-通信”一体化结构,减少数据搬运能耗;
- 台积电CoWoS等封装技术支持不同工艺节点的裸片混合集成,突破单一制程限制。
三、重写芯片设计规则的三大方向
MaPU结合3D堆叠,推动设计规则从“平面静态”向“三维动态”演进:
1. 设计目标重构:
- 从追求晶体管微缩转向“空间利用率优化”,以3D堆叠实现等效5nm性能(如7nm堆叠芯片达5nm水平);
- 英特尔、华为通过Chiplet技术降低对先进光刻机的依赖,提升刻蚀工艺地位。
2. 系统架构动态化:
- 硬件资源按需重组:MaPU的指令集可动态分配计算单元,避免ASIC的固化缺陷;
- 光子互联(如英伟达CIO)解决3D堆叠的通信瓶颈,能耗低至3.5 pJ/bit。
3. 生态协同升级:
- 配套三维工业软件链(如思朗“天穹”平台)实现从网格到O-Voxel的秒级转换,支撑科学智能新范式;
- 开源指令集(如RISC-V)降低定制门槛,推动模块化设计普及。
四、挑战与产业影响
关键技术瓶颈:
散热问题(热源叠加导致热密度飙升);
良率成本(单层缺陷导致整体报废,需预筛选技术)。
产业竞争格局:
中国通过MaPU实现架构级自主创新(完全自主指令集,400+专利);
国际巨头加速布局:谷歌TPUv7液冷集群、英伟达Quantum-X光交换芯片等,争夺3D集成生态主导权。
未来方向:芯片设计规则的核心将从“如何缩小晶体管”转向“如何智能重组三维资源”,而MaPU与3D堆叠的协同,正成为后摩尔时代突破算力边界的关键路径。
