


Llama 3.1 将上下文长度扩展到了 128K,拥有 8B、70B 和 405B 三个版本,再次以一已之力抬高了大模型赛道的竞争标准。
对 AI 社区来说,Llama 3.1 405B 最重要的意义是刷新了开源基础模型的能力上限,Meta 官方称,在一系列任务中,其性能可与最好的闭源模型相媲美。
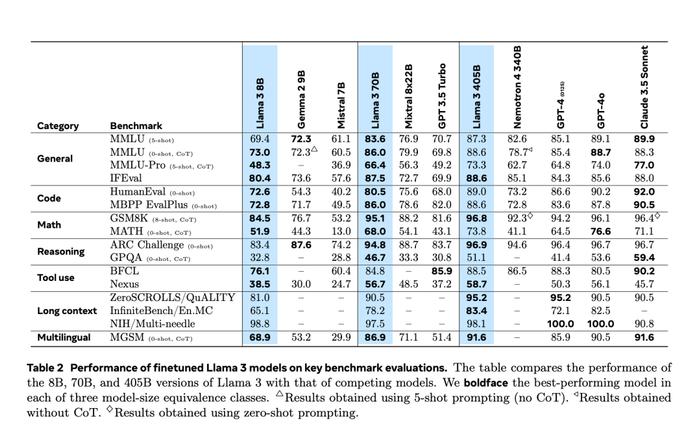
下表展示了当前 Llama 3 系列模型在关键基准测试上的性能。可以看出,405B 模型的性能与 GPT-4o 十分接近。
与此同时,Meta 公布了《The Llama 3 Herd of Models》论文,揭示了 Llama 3 系列模型迄今为止的研究细节。

论文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
接下来,让我们看一下论文内容。
Llama3 论文亮点
1、在使用 8K 上下文长度进行预训练后,Llama 3.1 405B 使用 128K 上下文长度进行连续训练,且支持多语言和工具使用。
2、与以前的 Llama 模型相比,Meta 加强了预处理和预训练数据的 Curation pipelines,以及后训练数据的质量保证和过滤方法。
Meta 认为,高质量基础模型的开发有三个关键杠杆:数据、规模和复杂性管理。
首先,与 Llama 的早期版本相比,Meta 在数量和质量两方面改进了用于预训练和后训练的数据。Meta 在大约 15 万亿的多语言 Token 语料库上对 Llama 3 进行了预训练,相比之下,Llama 2 只使用了 1.8 万亿 Token。
此次训练的模型规模远大于以前的 Llama 模型:旗舰语言模型使用了 3.8 × 10²⁵ 次浮点运算(FLOPs)进行预训练,超过 Llama 2 的最大版本近 50 倍。
基于 Scaling law,在 Meta 的训练预算下,当前的旗舰模型已是近似计算最优的规模,但 Meta 对较小模型进行的训练时间已经远超计算最优的时长。结果表明,这些较小模型在相同推理预算下的表现优于计算最优模型。在后训练阶段,Meta 使用了 405B 的旗舰模型进一步提高了 70B 和 8B 模型这些较小模型的质量。
3、为了支持 405B 模型的大规模生产推理,Meta 将 16 位 (BF16) 量化为 8 位 (FP8),从而降低了计算要求,并使模型能够在单个服务器节点上运行。
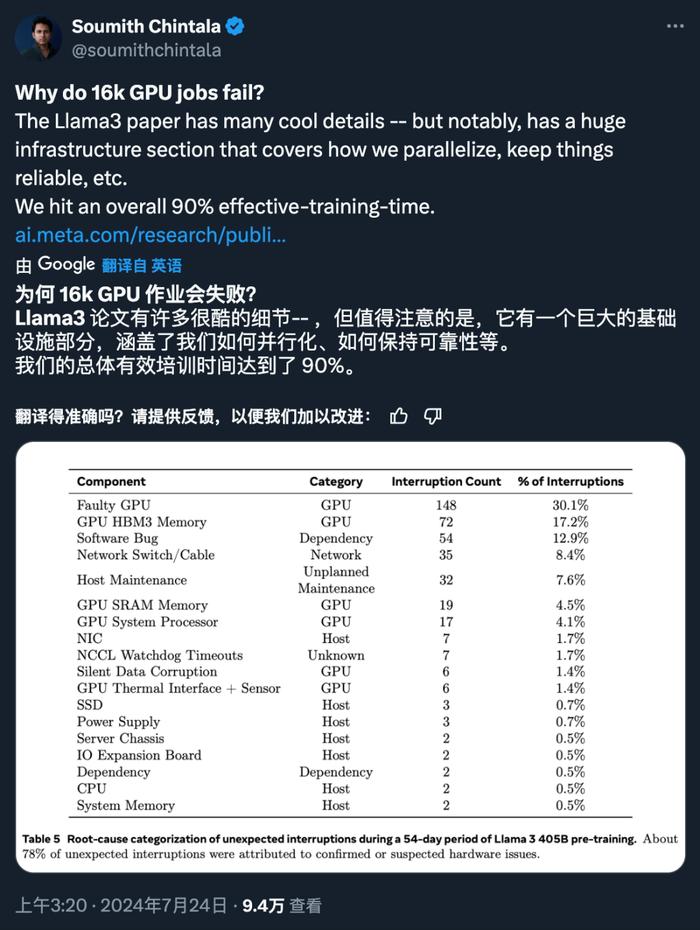
4、在 15.6T token(3.8x10²⁵ FLOPs)上预训练 405B 是一项重大挑战,Meta 优化了整个训练堆栈,并使用了超过 16K H100 GPU。
正如 PyTorch 创始人、Meta 杰出工程师 Soumith Chintala 所说,Llama3 论文揭示了许多很酷的细节,其中之一就是基础设施的构建。
5、在后训练中,Meta 通过多轮对齐来完善 Chat 模型,其中包括监督微调(SFT)、拒绝采样和直接偏好优化。大多数 SFT 样本由合成数据生成。
研究者在设计中做出了一些选择,以最大化模型开发过程的可扩展性。例如,选择标准的密集 Transformer 模型架构,只进行了少量调整,而不是采用专家混合模型,以最大限度地提高训练的稳定性。同样,采用相对简单的后训练程序,基于监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO),而不是更复杂的强化学习算法, 因为后者往往稳定性较差且更难扩展。
6、作为 Llama 3 开发过程的一部分,Meta 团队还开发了模型的多模态扩展,使其具备图像识别、视频识别和语音理解的能力。这些模型仍在积极开发中,尚未准备好发布,但论文展示了对这些多模态模型进行初步实验的结果。
7、Meta 更新了许可证,允许开发者使用 Llama 模型的输出结果来增强其他模型。
在这篇论文的最后,我们还看到了长长的贡献者名单:


这一系列因素,最终造就了今天的 Llama 3 系列。
当然,对于普通开发者来说,如何利用 405B 规模的模型是一项挑战,需要大量的计算资源和专业知识。
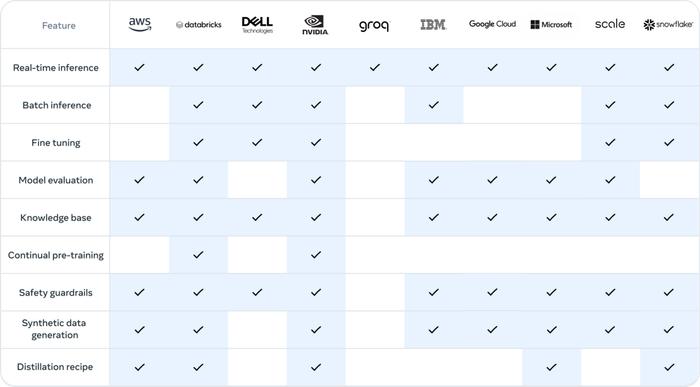
发布之后,Llama 3.1 的生态系统已准备就绪,超过 25 个合作伙伴提供了可与最新模型搭配使用的服务,包括亚马逊云科技、NVIDIA、Databricks、Groq、Dell、Azure、Google Cloud 和 Snowflake 等。
更多技术细节,可参考原论文。

